【Rails】クエリーインターフェイスを✅
RUNTEQ卒業生が所属する会社のweb meetupを観覧して、つよつよはつよつよを引き寄せるんだなと感じ、一体どうやってそのつよつよの土俵に上がれば良いんだ嘆いている23期中野昴こと酒ケジュール作成中です。
さて、今回は、エビングハウス曲線やレミニセンス効果を狙うために、今のうちからActiveRecordについて学習していきたいと思います。
クエリーインターフェイスとは
データベースに問い合わせる際の窓口のこと
まんま日本語訳に直してみた。
APIがソフトウェアやプログラム、Webサービスの間をつなぐインターフェースのことを指すなら、ActiveModelのクエリーインターフェイスはDBとRailsを繋げる際の接合部分を指すのだろう。
どんなものが用意されているのか
公式を見ながらどんなSQL文が発行されるのかを確認してみる。
一つのレコードを取得したい時
find
引数に入れた値にマッチする主キーを持つレコードを一つ取り出す。マッチするレコードが無い場合は例外を吐き出す。
例外を出すということは、例外が起きないことが前提とされているからだろうか。感嘆詞の時は少なくともそうだったような。
irb > Alcohol.find(3)
Alcohol Load (2.3ms)
SELECT `alcohols`.*
FROM `alcohols`
WHERE `alcohols`.`id` = 3
LIMIT 1
=> #<Alcohol id: 3, name: "11500ボックス", alcohol_percentage: 0.0, alcohol_amount: 11500, description: "アルコール総量が11500mlのボックスです。", created_at: "2021-12-09 07:43:15.003750000 +0900", updated_at: "2021-12-09 07:43:15.003750000 +0900", image: nil>
引数に配列を入れることで複数のオブジェクトを取り出すことができる。
irb> Alcohol.find([3, 12])
Alcohol Load (4.0ms) SELECT `alcohols`.* FROM `alcohols` WHERE `alcohols`.`id` IN (3, 12)
=> [#<Alcohol id: 3, name: "11500ボックス", alcohol_percentage: 0.0, alcohol_amount: 11500, description: "アルコール総量が11500mlのボックスです。", created_at: "2021-12-09 07:43:15.003750000 +0900", updated_at: "2021-12-09 07:43:15.003750000 +0900", image: nil>, #<Alcohol id: 12, name: "7000ボックス", alcohol_percentage: 0.0, alcohol_amount: 7000, description: "アルコール総量が7000mlのボックスです。", created_at: "2021-12-09 07:43:15.038544000 +0900", updated_at: "2021-12-09 07:43:15.038544000 +0900", image: nil>]
find_by
与えられた条件で最初に該当したレコードを一つ取り出す。該当するオブジェクトが存在しない場合は、nilを返す。
irb(main):006:0> Alcohol.find_by name: "ビール"
Alcohol Load (2.7ms) SELECT `alcohols`.* FROM `alcohols` WHERE `alcohols`.`name` = 'ビール' LIMIT 1
=> #<Alcohol id: 25, name: "ビール", alcohol_percentage: 5.0, alcohol_amount: 350, description: "「醸造酒」の一つ。とりあえずビールでお馴染みのビール。乾杯、そしてキンキンに冷えた
ールを流し込もう...", created_at: "2021-12-09 07:43:15.504200000 +0900", updated_at: "2021-12-09 07:43:15.504200000 +0900", image: "beer.png">
Active Record クエリインターフェイス - Railsガイド
take
モデルのレコードを一つ取り出す。そもそもDBにレコードがあるのかを確認するときに使用する。
irb(main):003:0> Alcohol.take
Alcohol Load (1.7ms) SELECT `alcohols`.* FROM `alcohols` LIMIT 1
=> #<Alcohol id: 1, name: "12500ボックス", alcohol_percentage: 0.0, alcohol_amount: 12500, description: "アルコール総量が12500mlのボックスです。", created_at: "2021-12-09 07:43:14.973709000 +0900", updated_at: "2021-12-09 07:43:14.973709000 +0900", image: nil>
複数のレコードを取得して処理を実行したい時
each
全てのレコードを取得した後、一件一件に対して丁寧にオブジェクトを生成する。めっちゃメモリを食うから推奨されていない。
find_each
全てのレコードを取得した後、一つのブロックに納めて丸っとオブジェクトを生成する。デフォルトで1000件処理することができる。
特定のカラムを取得したい時
Alcohol.findの時は、select *が実行されているため、対象のオブジェクトにあるカラムを全て取得していた。いやいや、この名前と度数だけでいいんよ、他のカラムはいらないっすというときはselectを使う
Alcohol.select("name,alcohol_percentage").find(1)
Alcohol Load (1.4ms) SELECT name,alcohol_percentage FROM `alcohols` WHERE `alcohols`.`id` = 1 LIMIT 1
=> #<Alcohol id: nil, name: "12500ボックス", alcohol_percentage: 0.0>
重複するレコードはいらないんすよという場合は、distinctを使う
irb(main):015:0> Alcohol.select("alcohol_percentage")
Alcohol Load (2.6ms) SELECT `alcohols`.`alcohol_percentage` FROM `alcohols` /* loading for inspect */ LIMIT 11
=> #<ActiveRecord::Relation [#<Alcohol id: nil, alcohol_percentage: 0.0>, #<Alcohol id: nil, alcohol_percentage: 0.0>, #<Alcohol id: nil, alcohol_percentage: 0.0>, #<Alcohol id: nil, alcohol_percentage: 0.0>, #<Alcohol id: nil, alcohol_percentage: 0.0>, #<Alcohol id: nil, alcohol_percentage: 0.0>, #<Alcohol id: nil, alcohol_percentage: 0.0>, #<Alcohol id: nil, alcohol_percentage: 0.0>, #<Alcohol id: nil, alcohol_percentage: 0.0>, #<Alcohol id: nil, alcohol_percentage: 0.0>, ...]>
irb(main):015:0> Alcohol.select("alcohol_percentage").distinct
Alcohol Load (8.8ms) SELECT DISTINCT `alcohols`.`alcohol_percentage` FROM `alcohols` /* loading for inspect */ LIMIT 11
=> #<ActiveRecord::Relation [#<Alcohol id: nil, alcohol_percentage: 0.0>, #<Alcohol id: nil, alcohol_percentage: 5.0>, #<Alcohol id: nil, alcohol_percentage: 12.0>, #<Alcohol id: nil, alcohol_percentage: 6.0>, #<Alcohol id: nil, alcohol_percentage: 8.0>, #<Alcohol id: nil, alcohol_percentage: 3.0>, #<Alcohol id: nil, alcohol_percentage: 7.0>, #<Alcohol id: nil, alcohol_percentage: 40.0>, #<Alcohol id: nil, alcohol_percentage: 10.0>, #<Alcohol id: nil, alcohol_percentage: 15.0>, ...]>
Active Record クエリインターフェイス - Railsガイド
N + 1問題を回避したい時
N + 1問題とは
親テーブルから孫テーブルのデータを複数取得する際に、まず子テーブルに一回SQL文を発行してから孫テーブルに複数SQL文を発行してしまうことを指す。
まとめると、子データクエリーを投げる数(1)に対して、欲しいデータ数(N) が無駄に発行されてしまう問題のことを指す。
順番から考えると、N+1問題というよりは1+N問題と呼んだ方がイメージしやすい・
irb(main):020:0> alcohols = Alcohol.limit(10)
Alcohol Load (0.4ms) SELECT `alcohols`.* FROM `alcohols` /* loading for inspect */ LIMIT 10
この問題を回避する方法はいくつかある。
試しに、allを使った場合とincludeを使った場合を比較してN+1問題を理解してみる。
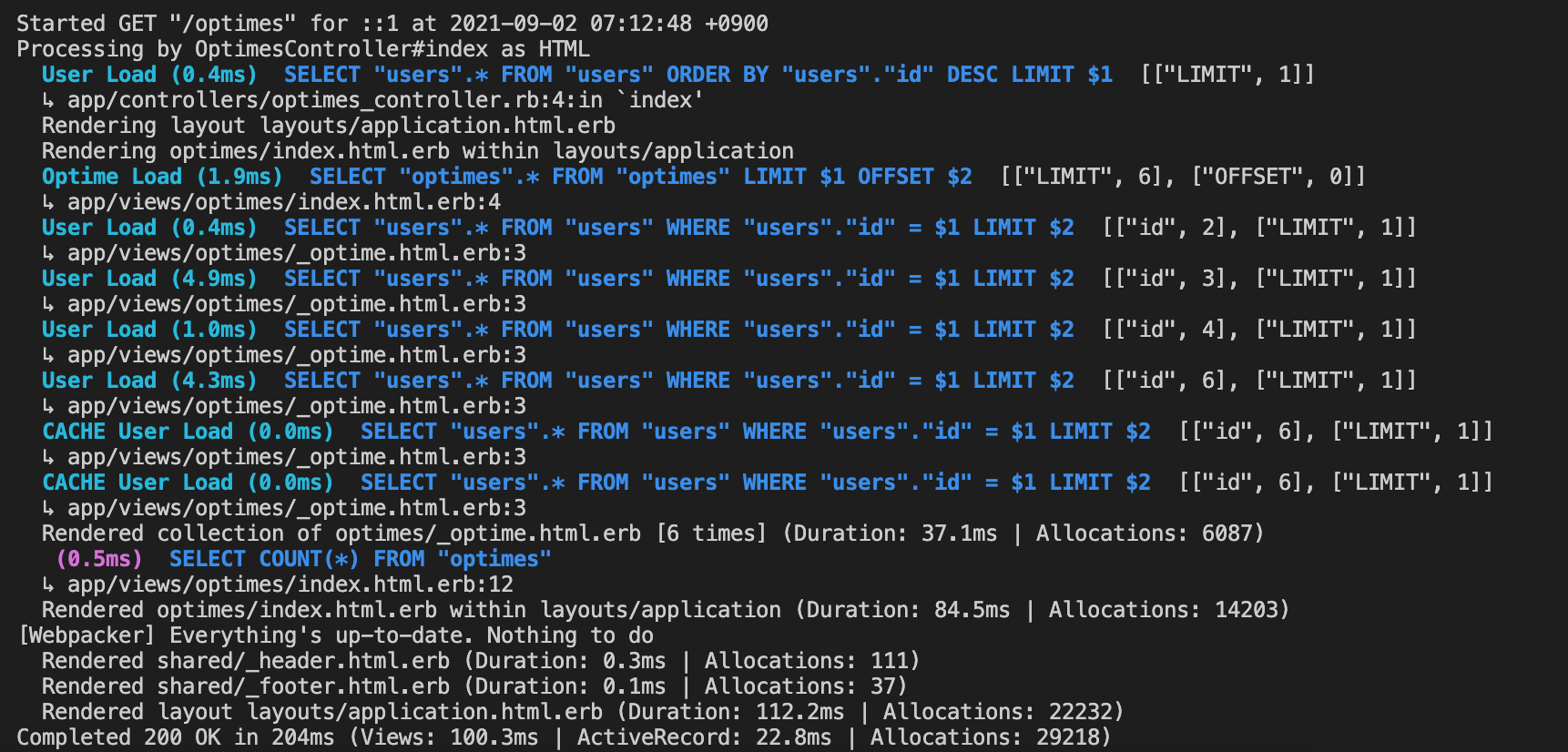
allを使用した場合
<a href="https://gyazo.com/03381abc25abdc2b16e569af2d19bcee"><img src="https://i.gyazo.com/03381abc25abdc2b16e569af2d19bcee.png" alt="Image from Gyazo" width="861"/></a>
{kind=link}
Completed 200 OK in 204ms (Views: 100.3ms | ActiveRecord: 22.8ms | Allocations: 29218)
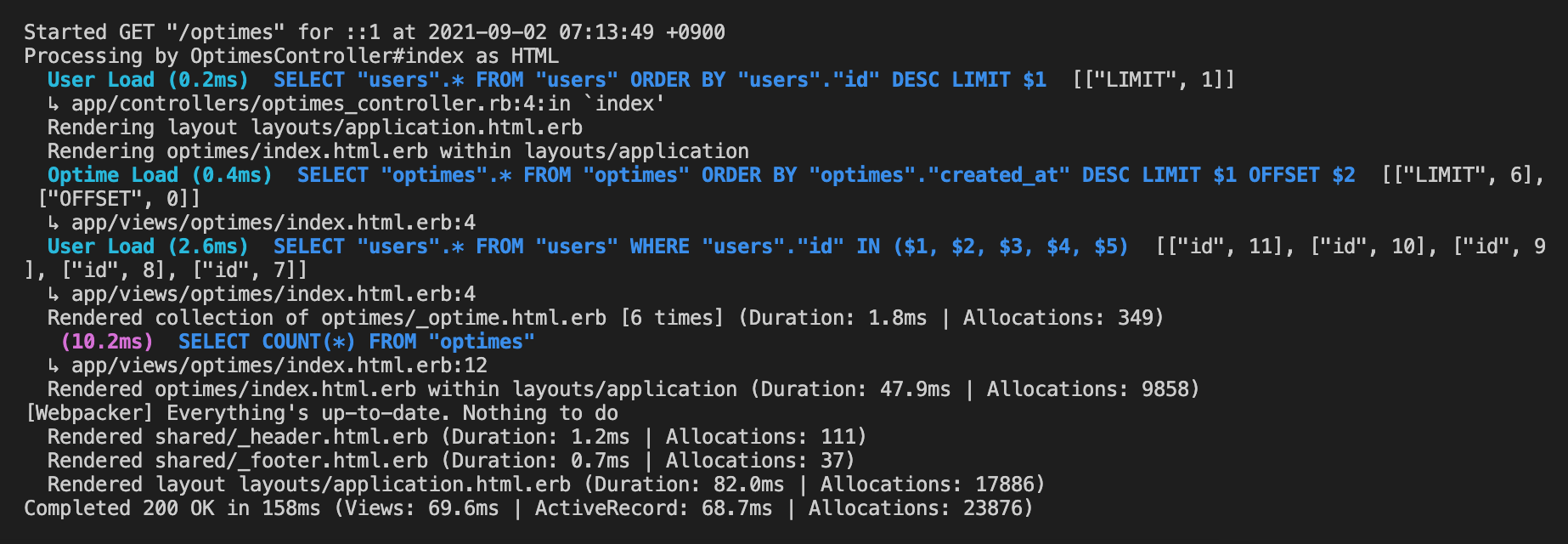
includeを使用した場合
<a href="https://gyazo.com/5767a3f7c5ecd8f0f9a2cf92005ddafd"><img src="https://i.gyazo.com/5767a3f7c5ecd8f0f9a2cf92005ddafd.png" alt="Image from Gyazo" width="923"/></a>
{kind=link}
Completed 200 OK in 158ms (Views: 69.6ms | ActiveRecord: 68.7ms | Allocations: 23876)
includeとallを比較してみると、includeの方がviewにレンダリングする時間が短いことがわかる。includeを使用すると事前にActiverecordからデータをひっぱってきて、その後にviewにレンダリングするため、viewsに表示させるときにかかる時間が短いみたいだ。
preloadとeager_load,includeの使い分け
-
includesはなるべく利用しない方が良いpreloadとeager_loadの使い分けをよしなにやってくれてしまうため、予期せぬ挙動をする可能性がある。熟練者はしっかり使い分けるそうで。
- 理由:意図しない挙動を防ぐため
- 代わりに、
preloadかeager_loadを使う
-
preload指定したassociationをLEFT OUTER JOINで引いてキャッシュする。クエリの数が1個で済むので場合によってはpreloadより速い。しっかりjoinしているため、whereで参照元のデータを絞り込み検索することができる。
三つの中で一番クエリ速度が早い
irb(main):032:0> User.preload(:analyzes) User Load (2.7ms) SELECT `users`.* FROM `users` /* loading for inspect */ LIMIT 11 Analyze Load (3.2ms) SELECT `analyzes`.* FROM `analyzes` WHERE `analyzes`.`user_id` IN (1, 2, 3, 4)- どんな場合に使うといいか : 多対多のアソシエーションの場合
- できないこと : アソシエーション先のデータ参照(Whereによる絞り込みなど)
- 注意 : データ量が大きいと、IN句が大きくなりがちで、メモリを圧迫する可能性がある
-
eager_loadはどんな場合に使うといいか指定したassociationを複数のクエリに分けて引いてキャッシュする。
UserとAnalyzeを紐付けてUser情報を取得したい場合。二つとも別のクエリを発行しているため、whereは使えない。
irb(main):031:0> User.eager_load(:analyzes) SQL (3.1ms) SELECT DISTINCT `users`.`id` FROM `users` LEFT OUTER JOIN `analyzes` ON `analyzes`.`user_id` = `users`.`id` /* loading for inspect */ LIMIT 11 SQL (10.5ms) SELECT `users`.`id` AS t0_r0, `users`.`nickname` AS t0_r1, `users`.`email` AS t0_r2, `users`.`crypted_password` AS t0_r3, `users`.`salt` AS t0_r4, `users`.`role` AS t0_r5, `users`.`created_at` AS t0_r6, `users`.`updated_at` AS t0_r7, `users`.`avatar` AS t0_r8, `users`.`reset_password_token` AS t0_r9, `users`.`reset_password_token_expires_at` AS t0_r10, `users`.`reset_password_email_sent_at` AS t0_r11, `analyzes`.`id` AS t1_r0, `analyzes`.`user_id` AS t1_r1, `analyzes`.`total_points` AS t1_r2, `analyzes`.`created_at` AS t1_r3, `analyzes`.`updated_at` AS t1_r4, `analyzes`.`description` AS t1_r5, `analyzes`.`shuchedule` AS t1_r6, `analyzes`.`next_motivation` AS t1_r7, `analyzes`.`alcohol_strongness` AS t1_r8 FROM `users` LEFT OUTER JOIN `analyzes` ON `analyzes`.`user_id` = `users`.`id` WHERE `users`.`id` IN (3, 2, 1, 4) /* loading for inspect */- 1対1あるいはN対1のアソシエーションをJOINする場合(belongs_to, has_one アソシエーション)
- JOINした先のテーブルの情報を参照したい場合(Whereによる絞り込みなど)
-
joinsはどんな場合に使うかアソシエーションを組んで結合元のデータを全て取得したいとき
irb(main):030:0> User.joins(:analyzes) User Load (11.5ms) SELECT `users`.* FROM `users` INNER JOIN `analyzes` ON `analyzes`.`user_id` = `users`.`id` /* loading for inspect */ LIMIT 11- メモリの使用量を必要最低限に抑えたい場合
- JOINした先のデータを参照せず、絞り込み結果だけが必要な場合
- 逆に言うと、引用先のデータを参照しない場合、使用しないほうがいいです
対Nのアソシエーションの場合はpreload
データ量が増えるほど、eager_loadよりも、preloadの方がSQLを分割して取得するため、レスポンスタイムは早くなる
対1のアソシエーションの場合はeager_load
データ量が増えても、1回のSQLでまとめて取得した方が効率的な場合が多い
https://qiita.com/k0kubun/items/80c5a5494f53bb88dc58
pluck
1つのモデルで使用されているテーブルからカラム (1つでも複数でも可) を取得するクエリを送信する
irb(main):034:0> Alcohol.pluck(:id,:name)
(7.3ms)
SELECT `alcohols`.`id`, `alcohols`.`name`
FROM `alcohols`
Active Record クエリインターフェイス - Railsガイド
SQL文はわかるけど、、な時
find_by_sqlを使うことで、生SQLでデータベースからデータを取得することができる。
Alcohol.find_by_sql("SELECT `users`.* FROM `users` INNER JOIN `analyzes` ON `analyzes`.`user_id` = `users`.`id` /* loading for inspect */ LIMIT 11")
Alcohol Load (1.8ms)
SELECT `users`.*
FROM `users`
INNER JOIN `analyzes`
ON `analyzes`.`user_id` = `users`.`id` /* loading for inspect */
LIMIT 11
Active Record クエリインターフェイス - Railsガイド
一言
なんか3ヶ月前よりもSQL文が理解できてるきがする、、!気のせいかな?